October 25, 2020
L'encodage de caractère dans Rstudio
L’encodage de caractère c’est quoi ?
Un ordinateur ne peut stocker que des nombres, ou plus précisément des 0 et des 1 (des « bits ») qu’on regroupe pour former des nombres en binaire.
Comment fait-on alors pour écrire du texte ? La réponse est toute bête : on associe à chaque caractère (une lettre, un signe de ponctuation, une espace…) un nombre. Un texte est alors une suite de ces nombres, on parle de chaîne de caractères.
L’encodage est une table de correspondance entre un ordinateur et le langage humain (français, anglais, chinois…).
Si vous voulez aller plus loin sur l’encodage et son histoire, nous vous recommandons ce tutoriel : Comprendre les encodages.
UTF-8: l’encodage référence
Au fil des années plusieurs encodages ont été créés. Un a finalement réussi à regrouper presque tous les langages. Il s’agit de L’Unicode. Il y a plusieurs implémentations concrètes d’Unicode. Le plus célèbre est “UTF-8”. L’UTF-8 est le seul encodage vers lequel, aujourd’hui, on puisse convertir vers et depuis (pratiquement) toutes les langues au monde.
Suivant le système d’exploitation que vous utilisez, l’encodage par défaut n’est pas le même.
Par exemple, les systèmes d’exploitation Linux utilisent en général par défaut l’encodage UTF-8. Par contre sous Windows (en France) l’encodage par défaut est généralement Windows 1252.
L’encodage sur Linux
Si vous travailler avec des VM notamment via des plateformes cloud (CGP, AWS, AZURE…), il y a de fortes chances que vous travaillez sous Linux. Par conséquent l’encodage par défaut est UTF-8. Ceci implique que lors de l’importation ou de l’exportation des données, les caractères seront encodés par défaut en UTF-8.
Illustration des problèmes liés à l’encodage sur les données
Exemple 1 : VM Linux vers Excel Bureau
Construisons une table depuis notre environnement Linux avec des caractères spéciaux:
df <- tibble::tibble(nom = c("Éric", "Nathanël"), entreprise = c("Réseau de Transport d'électricité", "Réseau de Transport d'électricité"))
df## # A tibble: 2 x 2
## nom entreprise
## <chr> <chr>
## 1 Éric Réseau de Transport d'électricité
## 2 Nathanël Réseau de Transport d'électricitéSauvegardons notre table dans un csv.
readr::write_csv2(df, "df.csv")Exportons ensuite le fichier vers notre poste windows (Onglet Files puis More > Export) et ouvrons le dans excel en double-cliquant sur le fichier.
Normalement la table ressemble à ca:
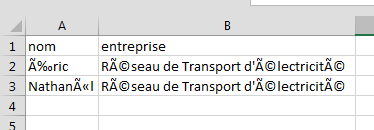
Les caractères spéciaux ont été transformés en des caractères “bizarres”.
Exemple 2: Excel Bureau vers Linux
Créons un fichier csv depuis excel sur notre poste bureautique avec des caractères spéciaux.
On le télécharge sur Rstudio dans Linux (bouton Upload dans l’onglet Files) et on l’importe en mémoire
df2 <- readr::read_csv2("/data_post/example_encoding.csv")
df2A l’affichage, les caractères spéciaux ont été transformés en des caractères “bizarres”.
Voici illustré en deux exemples, les problèmes d’encodage que vous pourriez avoir. Ce qui s’est passé, c’est que comme Linux et windows n’utilise pas le même encodage par défaut, certains caractères ont été mal retranscrits.
Bien gérer l’encodage
A la lecture des données
La solution pour bien lire les données (que ce soit dans Linux ou Windows) est de spécifier l’encodage qui a servi pour enregistrer les données.
Dans Excel
Dans la première illustration, il faut ouvrir le fichier csv dans excel en spécifiant UTF-8 comme encodage.
Pour cela, il faut ouvrir une page excel vierge puis aller dans DONNÉES > Fichier texte. Sélectionnez votre fichier. Dans l’assistant d’importation de texte à l’étape 1 vous avez Origine du fichier. Sélectionnez 65001 : Unicode (UTF-8) puis suivez le reste des étapes jusqu’à la fin.
Après importation, les caractères spéciaux devraient s’afficher normalement.
Dans Linux
Dans la deuxième illustration, il faut lire le fichier csv dans Linux en spécifiant WINDOWS-1252 comme encodage.
df2 <- readr::read_csv2("/data_post/example_encoding.csv", locale = readr::locale(encoding = "WINDOWS-1252"))
df2Presque toutes les fonctions de lecture de fichier dans R ont une option qui permet de spécifier l’encodage (
fileEncodingpourread.\*,encodingpourfread,localpourread_*…)
Vous pouvez aussi modifier l’encodage des caractères après lecture avec parse_character.
df2 <- readr::read_csv2("/data_post/example_encoding.csv")
df2
# On change l'encodage de tous les types caractères
df2 <- dplyr::mutate_all(df2, function(x){readr::parse_character(x, locale = readr::locale(encoding = "WINDOWS-1252"))})
df2A l’écriture des données
A l’écriture des données vous avez deux choix possibles :
- Spécifier l’encodage lors de l’écriture
Pour faire cela nous allons utiliser les fonctions de base dans R file et write.csv2
con<-file('df.csv',encoding="WINDOWS-1252")
write.csv2(df,file=con)NOTE: Il n’a pas été prévu la spécification de l’encodage avec la fonction
write_csv2dereadrnifwritepourdata.table. Ils écrivent toujours en UTF-8. La requête précédente ne changera donc pas l’encodage si vous utilisezwrite_csv2(fwritene prend pas de paramètre de typeconnection).
- Rajouter un Indicateur d’ordre des octets (Byte Order Mark)
En Unicode, l’indicateur d’ordre des octets ou BOM (pour l’anglais byte order mark) est une donnée qui indique l’utilisation d’un encodage Unicode ainsi que l’ordre des octets, généralement situé au début de certains fichiers texte.
Pour dire simple le BOM spécifie lors de l’écriture que le fichier est encodé en Unicode (UTF-8 dans notre cas).
Pour faire cela, on utilise la fonction write_excel_csv2 de readr
readr::write_excel_csv2(df, "df-UTF8-BOM.csv")A l’ouverture dans tout autre environnement (Excel bureau dans notre cas), L’encodage UTF-8 sera automatiquement utilisé.
Et mes scripts dans tout ça 🤔?
Si vous rédigez/récupérez des scripts rédigés dans deux environnements différents (Rstudio en local sur votre poste Windows et Linux) vous aurez surement des soucis avec les caractères spéciaux lors du passage d’un environnement à l’autre.
Pour éviter ces désagréments dans vos scripts, nous vous conseillons fortement de mettre l’encodage UTF-8 par défaut sur votre Rstudio Linux et windows.
Pour le faire, allez dans Tools > Global Option > Code > Saving > Default text encoding et mettez UTF-8.
Si vous disposez d’un script déjà écrit dans un autre encodage, vous pouvez le réouvrir en spécifiant le bon encodage. Ouvrez le fichier puis allez dans File > Reopen with encoding.
Vous pouvez ensuite faire File > Save with encoding pour l’enregistrer en UTF-8.
Nos conseils 🙂
UTF-8, j’utiliserai…
- Réglez votre R local en UTF8
- Réglez l’encodage à la lecture de vos fichiers
- Convertissez vos scripts en UTF-8 s’ils ne le sont pas
- Si vous rencontrez des problèmes de caractères bizarres, c’est surement lié à un mauvais encodage utilisé à la lecture.
- Dans R il y a des fonctions qui peuvent aider à identifier l’encodage si vous avez des doutes (
readr::guess_encodingpar exemple)
Quelques articles sur l’encodage dans R
comments powered by Disqus